
Dans le problème que j'essaie de résoudre, mon domaine de sortie est centré sur zéro, entre -1 et 1. Lors de la recherche de fonctions d'activation, j'ai remarqué que ReLu génère des valeurs comprises entre 0 et 1, ce qui signifie essentiellement que votre sortie est tout négatifs ou tous positifs.
Cela peut être mappé vers le domaine approprié par normalisation inverse, mais ReLu est conçu pour déterminer la "force" d'un neurone dans une seule direction, mais dans mon problème, je dois déterminer la force d'un neurone dans l'un des deux sens. Si j'utilise tanh, je dois m'inquiéter de la disparition / explosion des dégradés, mais si j'utilise ReLu, ma sortie sera toujours "biaisée" vers des valeurs positives ou négatives, car essentiellement des valeurs très petites devraient être mappées sur un domaine postitif et grand valoriser un domaine à exclure ou vice versa.
Autre info: j'ai utilisé ReLu et cela fonctionne bien mais je crains que ce ne soit pour de mauvaises raisons. La raison pour laquelle je dis cela est qu'il semble que pour le domaine pos ou neg approcher des valeurs plus petites signifiera une connexion plus forte jusqu'à un certain point, puis il ne sera pas activé du tout. Oui, le réseau peut techniquement travailler (probablement plus dur que nécessaire) pour garder tout le domaine des sorties de train dans l'espace positif, mais si une valeur dépasse les limites de l'ensemble de formation, elle sera inexistante? alors qu'en réalité il devrait être encore plus actif
Quelle est la manière appropriée de traiter les domaines de sortie centrés sur zéro?
3 Réponses :
Premièrement, vous n'avez pas à mettre de fonction d'activation après la dernière couche de votre réseau neuronal. La fonction d'activation est requise entre les couches pour introduire la non-linéarité, elle n'est donc pas requise dans la dernière couche.
Vous êtes libre d'expérimenter différentes options:
out = tf.clip_by_value (sortie, -1.0, 1.0) À la fin, le ML est un processus d'essais et d'erreurs. Essayez différentes choses et trouvez quelque chose qui fonctionne pour vous. Bonne chance.
J'ai utilisé ReLu et cela fonctionne bien mais je crains que ce ne soit pour les mauvaises raisons. La raison pour laquelle je dis cela est que pour le domaine pos ou neg, l'approche de valeurs plus petites signifiera une connexion plus forte jusqu'à un certain point, ce qui ne me semble pas juste. Oui, le réseau peut techniquement travailler (probablement plus dur que nécessaire) pour garder tout le domaine des sorties de train dans l'espace positif, mais si une valeur dépasse les limites de l'ensemble d'entraînement, elle sera inexistante alors qu'en réalité elle devrait être encore plus actif.
La disparition des gradients pourrait très certainement être un problème survenant dans la pratique, par ex. dans les RNN, même avec de bons poids initiaux (les séquences de longueur supérieure à 5 sont même problématiques pour l'IIRC). De plus, ceux-ci satureraient facilement.
@SzymonMaszke Tout à fait d'accord avec vous. J'ai révisé un peu ma déclaration.
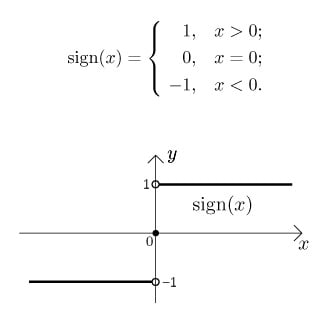
Je pense que vous devez utiliser la fonction Sign. Il est au centre zéro et a -1, 1 comme sortie.
Fonction de signe: https://helloacm.com/ wp-content / uploads / 2016/10 / math-sgn-function-in-cpp.jpg
Vous pouvez opter pour des variantes de ReLU qui produisent des valeurs avec une moyenne plus proche de zéro ou étant zéro ( ELU , CELU , PReLU et autres) et ayant d'autres traits spécifiques intéressants. De plus, cela aiderait à résoudre le problème des neurones mourants dans ReLU.
Quoi qu'il en soit, je ne suis au courant d'aucune recherche difficile prouvant l'utilité de l'un par rapport à l'autre, il est encore en phase d'expérimentation et dépend vraiment de ce dont je me souviens (veuillez me corriger si je me trompe).
Et vous devriez vraiment vérifier si la fonction d'activation est problématique dans votre cas, cela pourrait être tout à fait correct d'utiliser ReLU .
{kind=link}