
Supposons que j'ai une grande liste d'objets (milliers ou dizaines de milliers), chacun étiqueté avec une poignée de balises. Il existe des dizaines ou des centaines de balises possibles et leur utilisation suit une loi de pouvoir typique: Certaines balises sont utilisées extrêmement souvent, mais la plupart sont rares. Tous sauf les douzaines de couple la plus fréquente des balises pourraient être typiquement ignorées, en fait.
Maintenant, le problème est de visualiser la relation entre ces balises. Un nuage d'étiquettes est une belle visualisation de juste leurs fréquences, mais elle ignore quelles étiquettes se produisent avec lesquelles d'autres tags. Supposons que tag: la barre ne se produit que sur des objets aussi étiquetés: foo. Cela devrait être visuellement apparent. De même pour trois étiquettes qui ont tendance à se produire ensemble.
Vous pouvez faire une bulle de chaque étiquette et les laisser se chevaucher partiellement les uns avec les autres.
Techniquement, c'est un diagramme de Venn mais le traite de cette façon pourrait être difficile à manifester.
Par exemple, Google Graphiques peut créer des diagrammes de Venn, mais uniquement pour 3 ensembles ou moins (Tags):
http://code.google.com/apis/char/docs/ Galerie / Venn_Chart.html
La raison pour laquelle ils le limitent à 3 ensembles est que, plus et cela a l'air horrible.
Voir "EXCEPTIONS AUX NUMÉROS A BRESS DE SETS" sur la page Wikipedia: http://fr.wikipedia.org/ wiki / venn_diagrams
Mais ce n'est que si chaque intersection possible n'est pas vide. Si pas plus de 3 tags se produisent (peut-être après avoir lancé les tags rares), une collection de diagrammes de Venn pourrait fonctionner (avec la taille des bulles représentant la fréquence des étiquettes).
ou peut-être un graphique (comme dans les sommets et les bords) avec des bords visuellement plus épais ou plus mince pour représenter la fréquence de co-occurrence.
Avez-vous des idées ou des indications sur des outils ou des bibliothèques? Idéalement, je ferais cela avec JavaScript mais je suis ouvert à des choses comme R et Mathematica ou vraiment autre chose. Je suis heureux de partager certaines données réelles (vous risquerez si je vous dis que cela représente) si quelqu'un est curieux.
addendum : L'application que j'ai à l'origine eu à l'esprit était Tagtime mais cela me survient que cela chante également bien au problème de la visualisation de ses marques de marques de délicieuses.
4 Réponses :
Je créerais quelque chose comme celui-ci si vous ciblez le Web. Les bords reliant les nœuds pourraient être de couleur plus épaisse ou plus sombre, ou peut-être une force plus forte qui les relie-t-elle afin qu'elle soit proche de la distance. J'ajouterais également le nom de la balise à l'intérieur du cercle.
Certaines bibliothèques qui seraient très bonnes pour cela incluent:
Merci Jay! Je ne savais pas sur Protovis; C'est excellent. Quant à la plate-forme / langue, web / javascript est idéal mais si Mathematica ou R ou quelque chose a un excellent moyen de le faire, j'aimerais aussi savoir cela aussi. Quant à la mise en page dirigée par la force, ce que je n'aime pas, c'est que cela ne captive pas les relations de sous-ensemble. Peut-être quelque chose comme ça - vis.stanford.edu/protovis/ex/bubble.html < / a> - mais où les bulles peuvent être de l'autre.
Merci encore, Jay. Provis semble être JavaScript, pas flash, si je ne me trompe pas.
Si je comprends votre question correctement, une matrice d'image dans la matrice ci-dessous (que j'ai tourné à 90 degrés de sorte qu'il irait mieux dans cette fenêtre - des colonnes représentent donc des éléments étiquetés, et chaque ligne montre la présence ou l'absence d'une étiquette donnée à tous les éléments), j'ai simulé le Scénario dans lequel il y a 8 tags et 200 articles marqués . , un "0" est bleu et un Toutes les valeurs de cette matrice ont été sélectionnées de manière aléatoire (chaque élément étiqueté est huit tirages à partir d'une boîte composée de deux jetons, un bleu et un jaune (pas de balise et étiquette, respectivement). Donc, pas surprenant, il n'y a pas de visuel Preuve d'un motif ici, mais s'il y en a une dans vos données, cette technique, qui est morte simple à mettre en œuvre, peut vous aider à le trouver. J'ai utilisé r pour générer et parcourez les données simulées, en utilisant uniquement des graphiques de base (aucun packages externes ni bibliothèques): 
Je ne pense pas que ce type de visualisation aiderait à trouver des schémas dans les données étant donné qu'il existe des "milliers d'objets" et des "centaines de tags". L'image résultante ne sera probablement qu'une énorme image bruyante.
Un bon SÉGIATION est très important pour voir des motifs dans ce genre d'affichage
Notez que cela fonctionnerait car je n'ai pas testé cela, mais voici comment je démarrerais:
Vous pouvez créer une matrice comme Doug suggère dans sa réponse, mais au lieu d'avoir des documents en tant que lignes et étiquettes telles que des colonnes, vous prenez une matrice carrée où les étiquettes sont des lignes et des colonnes. La valeur de la cellule T1; T2 sera le nombre de documents étiquetés avec T1 et T2 (noter que vous obtiendrez une matrice symétrique car [t1; t2] aura la même valeur que [T2; T1]) .
Une fois que vous avez fait cela, chaque ligne (ou colonne) est un vecteur localisant la balise dans un espace avec des dimensions T. Les tags proches de chacun dans cet espace se produisent souvent ensemble. Pour visualiser la co-occurrence, vous pouvez ensuite utiliser une méthode pour réduire votre dimensionnalité spatiale ou toute méthode de clustering. Par exemple, vous pouvez utiliser une carte d'organisation auto-organisant Kohonen pour projeter votre espace T-Dimensions à un espace 2D, vous obtiendrez une matrice 2D dans laquelle chaque cellule représente un vecteur abstrait dans l'espace d'étiquette (ce qui signifie que le vecteur n'existe pas dans votre ensemble de données). Ce vecteur reflète une contrainte topologique de votre espace source et peut être considéré comme un vecteur "modèle" reflétant une co-occidence significative de certaines balises. De plus, les cellules près de chacune de cette carte représenteront des vecteurs proches les uns des autres dans l'espace source, vous permettant ainsi de cartographier l'espace d'étiquetage sur une matrice 2D.
La visualisation finale de la matrice peut être effectuée à bien des égards, mais je ne peux pas vous donner des conseils à ce sujet sans voir d'abord les résultats du traitement précédent.
Bien que ce soit un vieil fil, je viens de le trouver aujourd'hui.
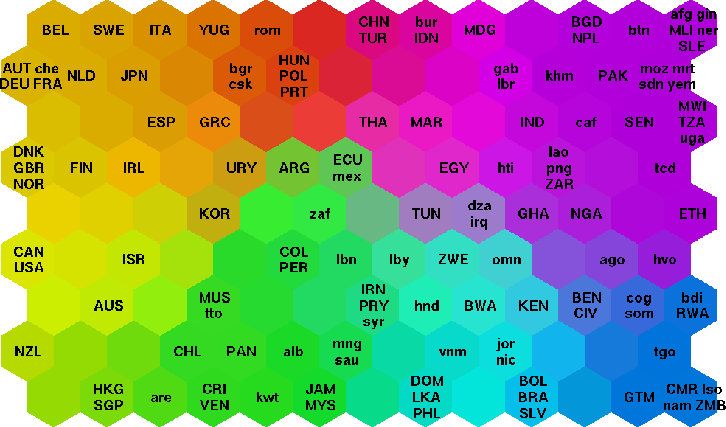
Vous voudrez peut-être aussi envisager d'utiliser un Carte auto-organisée .
Voici un exemple de carte auto-organisatrice pour la pauvreté mondiale. Il a utilisé 39 de ce que vous appelez vos "tags" pour organiser ce que vous appelez "objets".

{kind=link}
Vous semblez avoir laissé de côté le bit sur Programmation de votre question.
Il demande quelles bibliothèques qu'il devrait utiliser. À moins que, il souhaite vérifier un livre, c'est probablement une question de programmation.