
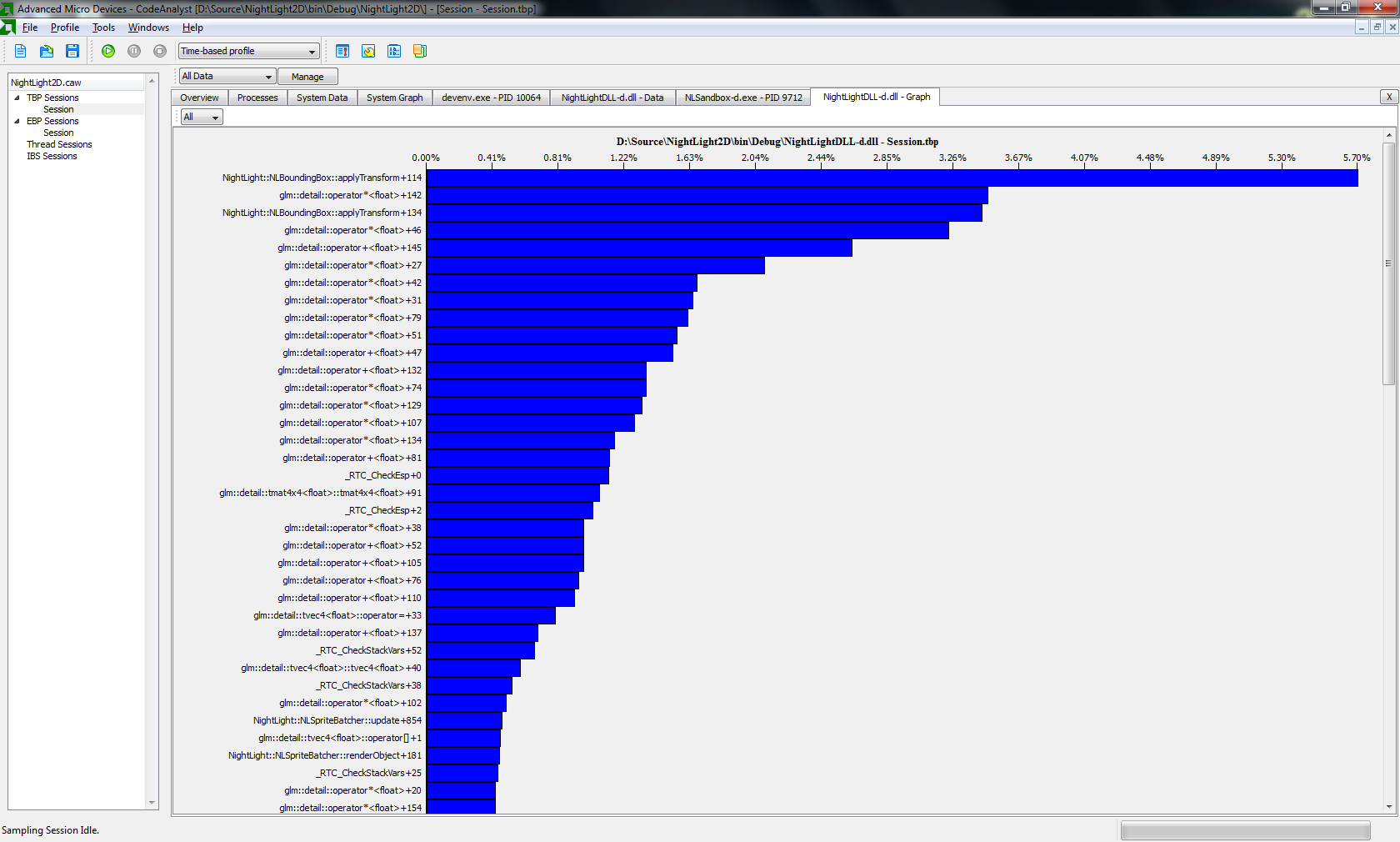
Je programmment un moteur OpenGL3 2D. Actuellement, j'essaie de résoudre un goulot d'étranglement. Veuillez donc la sortie suivante du profileur AMD: http://h7.ablead.de/img/profilerausa.png
Le Les données ont été effectuées en utilisant plusieurs milliers de sprites.
Cependant, à 50 000 sprites, le testApp est déjà inutilisable à 5 images par rapport à 5 fps.
Ceci montre que mon goulot d'étranglement est la fonction de transformation que j'utilise.
C'est la fonction correspondante:
http://code.google.com/p/nightlight2D /source/browse/nightlightdll/nlboundll/nlboundingbox.cpp#130 Je ne peux pas faire cela dans le shader, parce que je lâche toutes les sprites à la fois. Cela signifie que je dois utiliser la CPU pour calculer les transformations. Ma question est la suivante:
Quelle est la meilleure façon de résoudre ce goulot d'étranglement? Je n'utilise aucun guichet automatique de threads, alors lorsque j'utilise VSYNC, je reçois aussi une performance supplémentaire, car il attend que l'écran se termine. Cela me dit que je devrais utiliser le filetage. L'autre sens d'aller serait d'utiliser opencL peut-être? Je veux éviter Cuda, car autant que je sache, cela ne fonctionne que sur les cartes NVIDIA. Est-ce correct? Post Scriptum: Vous pouvez télécharger une démo ici, si vous le souhaitez: http://www63.zippyshare.com/v/45025690/file.html Veuillez noter que cela nécessite VC + +2008 installé, car il s'agit d'une version de débogage pour exécuter un profileur.
4 Réponses :
La première chose que je ferais est de concaténer votre rotation et de transformer les matrices en une matrice avant de saisir la boucle ... De cette façon, vous ne calculez pas deux multiplications à matrice et un vecteur sur chaque boucle; Au lieu de cela, vous ne seriez que multiplier un seul vecteur et matrice. Deuxièmement, vous voudrez peut-être examiner votre boucle, puis compiler avec un niveau d'optimisation plus élevé (sur g ++ J'utiliserais au moins -O2 , mais je ne suis pas familier Avec MSVC, vous devrez donc traduire ce niveau d'optimisation vous-même). Cela éviterait les frais généraux que les branches dans le code risquent, en particulier sur les cache-flushes. Enfin, si vous ne l'avez pas déjà examiné, recherchez des optimisations SSE puisque vous traitez de vecteurs.
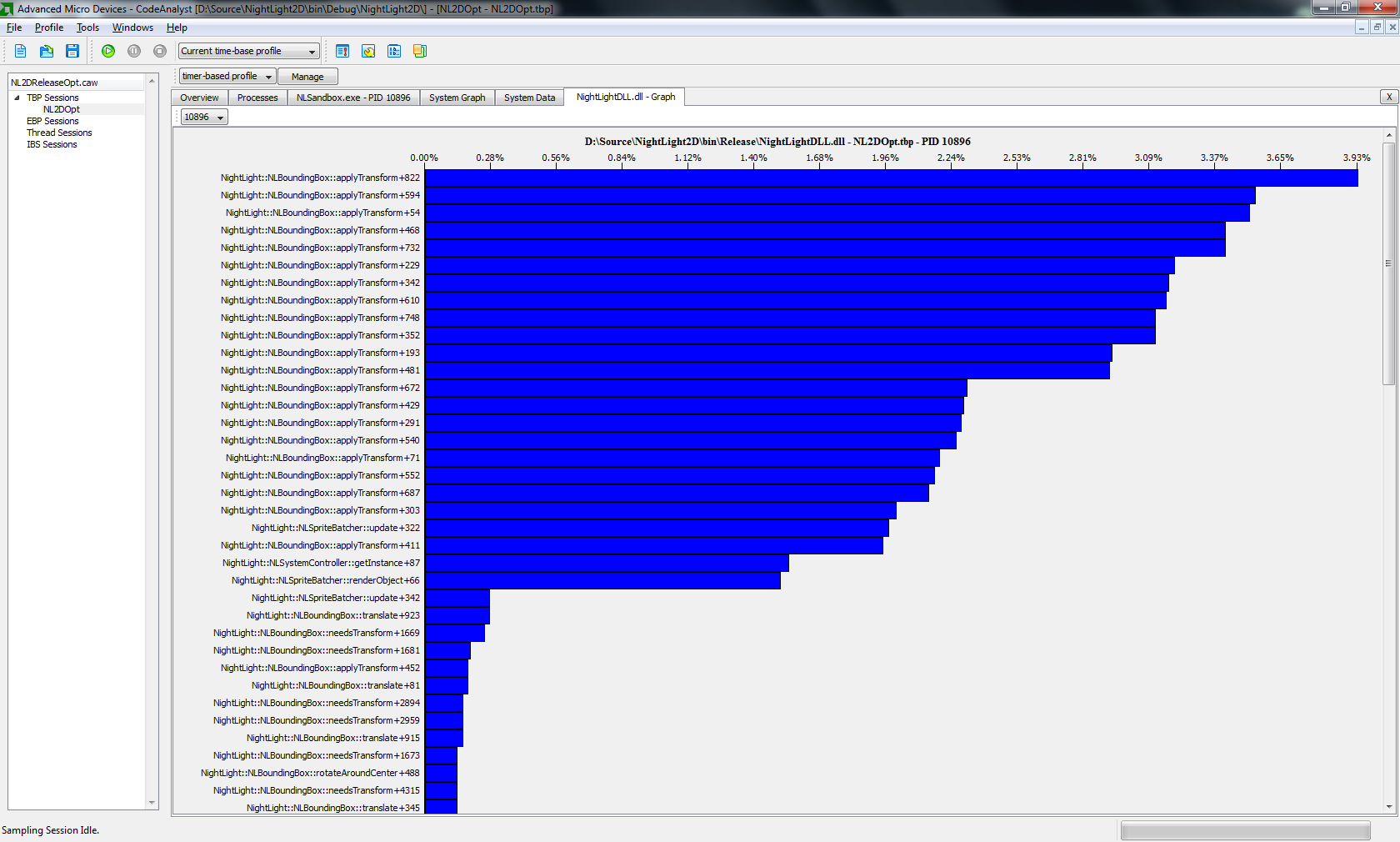
Ceci un profil du binaire optimisé: H3.Bload.de/img/OPT_Profile1D84.png Cela ne le supprime pas vraiment. De plus, I Haev a déplacé la multouche des 2 matrices hors de la boucle (comment pourrais-je superviser cela -.-) mais toujours, cela ne vous aide pas vraiment. Avec 50k Sprites, tous bouger et tournant chaque image, j'ai gagné 1 cadre et quelques ms. Rien de gros. J'ai aussi désactivé RTTI.
Désolé d'entendre que vous n'avez qu'un seul FPS en dehors de cela ... quel genre de machine utilisez-vous cela? Vous avez également une matrice de rotation et transformez la matrice statique suffisante pour que vous puissiez réellement mettre en cache la valeur de la multiplication des deux matrices (c'est-à-dire que vous ne les multipliez qu'une fois dans votre instance de classe NBoundingbox )? Pouvez-vous mettre en cache d'autres valeurs telles que les transformations elles-mêmes?
AMD5200 Dualcore avec une RAM ATI890HD 1 Go. Non, je ne peux pas la mettre en cache plus loin. M_ROTATION et M_TRANSLATION sont les matrices pour la rotation et le mouvement de puits et dans cette témoignage, chaque sprite est déplacé et tourné vers le test de contrainte. Et chaque sprite a sa propre transformation et sa position de. Quand ils ne bougent pas ou ne tournent pas du tout, j'ai environ 50 fps sans VSYNC. Tiny.cc/dt5f9
Quelle carte vidéo est un ATI890HD? ... BTW, avec seulement un double noyau, vous pouvez essayer le pipeline, mais il y aurait une certaine contention, c'est-à-dire que vous vous retrouveriez avec beaucoup de stalles
HD4890, mon 4 ne fonctionne plus bien> _>. Besoin d'un nouveau clavier.
Donc, oui, puisqu'il semble que la route d'optimisation de la CPU ne fonctionne pas trop bien, je suppose que vous n'auriez qu'une option pour un type de vitesse d'ordre d'ordre d'ordre serait d'utiliser OPENCL. Ce noyau est assez minuscule et ne devrait pas être un problème de portage. Malheureusement, ma compréhension de Opencl est un peu limitée, je ne peux donc pas vous dire quel type de contention vous pouvez voir au niveau du conducteur entre OpenGL et Opencl. Faire simplement une transformation sur des objets de 50 000 que je penserais devrait être assez simple pour un GPU.
BTW, je lisais le commentaire de Datenwolf ... Opencl peut être trop lourd un marteau pour cela ... Je ne suis pas un expert sur les shaders, mais ses commentaires semblent être une solution attrayante.
L'affectation à l'intérieur de la boucle pourrait être un problème, je ne connais cependant pas à la bibliothèque. Le déplaçant à l'extérieur de la boucle et faire les tâches de terrain pourraient vous aider. Déplacer les transformations en dehors de la boucle aiderait également. Edit: p> C'est plus dans ce domaine de ce que je pensais. P> glm::vec4 transformed[6];
for (size_t i = 0; i < 6; i++) {
transformed[i].x = vertices[i].x;
transformed[i].y = vertices[i].y;
transformed[i].z = vertices[i].z;
transformed.w = 1.f; // ?
}
glm::mat4 translation = m_rotation * m_translation;
for (size_t i = 0; i < 6; i++) {
/* I can't find docs, but assume they have an in-place multiply
transformed.mult(translation);
// */
}
for (size_t i = 0; i < 6; i++) {
vertices[i].x = transformed[i].x;
vertices[i].y = transformed[i].y;
}
J'ai déplacé les 2 calculs de matrices hors de la boucle, m_rotation * m_translation, mais encore seulement 1 cadre gagné.
"Je ne trouve pas de trouver des documents, mais suppose qu'ils ont une multiplication sur place" un vecteur / matrice de la place multiplie devraient créer un temporaire pour stocker le résultat, puis le copier dans l'original. Ou cela copierait l'original et se multiplierait dans l'original. De toute façon, vous ne gagnez rien comparé à l'utilisation de l'opérateur *. Copy-Elision devrait vous éviter de tout excès de copie du retour temporaire retourné. Les deux méthodes auraient une copie temporaire et feraient une copie, de sorte que les deux méthodes sont efficacement équivalentes.
@Nicol je m'attendrais à ce que ce soit le cas, honnêtement. Il est difficile de faire quoi que ce soit avec cela, mais devinez des choses à essayer depuis que nous n'avons qu'un extrait. :)
Je ne peux pas faire ça dans le shader, car je lâche toutes les sprites à la fois. Cela signifie que je dois utiliser la CPU pour calculer les transformations.
Cela ressemble de manière suspectueusement une optimisation prématurée que vous avez faite, sous l'hypothèse que le lotting est la chose la plus importante que vous puissiez faire et que vous avez donc structuré votre rendu autour de la plus grande quantité d'appels de dessins. Et maintenant, il revient pour vous mordre.
Ce que vous devez faire n'est pas moins de lots. Vous devez avoir le bon nombre de lots. Vous savez que vous êtes allé trop loin avec le loting lorsque vous forgez GPU Vertex se transforme en faveur des transformations de la CPU.
Comme Datenwolf a suggéré, vous devez obtenir un instancement d'accéder à la transformation sur le GPU. Mais même dans ce cas, vous devez annuler une partie du sur-batching que vous avez ici. Vous n'avez pas beaucoup parlé de quel type de scène vous rendu (Tilemplas avec des sprites sur le dessus, un grand système de particules, etc.), il est donc difficile de savoir quoi suggérer.
Aussi, GLM est une bibliothèque de mathématiques fine, mais c'est pas conçu pour une performance maximale. Ce n'est généralement pas ce que j'utiliserais si je devais transformer 300 000 sommets sur la CPU, chaque cadre.
Si vous insistez sur vos calculs sur la CPU, vous devriez faire les mathématiques vous-même.
En ce moment, vous utilisez des matrices 4x4 dans un environnement 2D, où une matrice 2x2 pour la rotation et un vecteur simple de la traduction devraient suffire. C'est 4 multiplications et 4 ajouts pour la rotation, ainsi que deux ajouts de traduction.
Si vous avez absolument besoin de deux matrices (parce que vous devez combiner la traduction et la rotation), ce sera toujours beaucoup moins que ce que vous avez maintenant. Mais vous pouvez également "manuellement" combiner ces deux en déplaçant la position du vecteur, en rotation, puis le reculez à nouveau, ce qui pourrait peut-être être un peu plus rapide que les multiplications, bien que je ne suis pas sûr de cela.
comparé aux opérations que ces matrices 4x4 font en ce moment, c'est beaucoup moins.
+1 ... C'est une bonne idée, bien que des matrices plutôt que 2x2 et un vecteur de transformation, il serait probablement préférable d'utiliser une matrice 3x3 avec des coordonnées homogènes pour maintenir la linéarité des rotations et des traductions. En d'autres termes, si vous utilisez une matrice de rotation 2x2 et un vecteur de traduction, vous devez utiliser un ordre très spécifique pour inverser les transformés et vous perdez la possibilité de concaténer des rotations et des traductions. Les matrices homogènes 3x3 conserveront la linéarité de la translation et des rotations, et vous pouvez concaténer une série de transformations en une matrice unique.
{kind=link}
{kind=link}
Bien sûr, vous pouvez utiliser un shader, le loting n'empêchera pas cela.
S'il vous plaît élaborer à ce sujet. Ce que je veux dire, c'est que je ne peux pas calculer la transformation de chaque sprite dans le shader, car je dessine tout Sprite en un avec 1 dessiné.
En tant que mis à l'écart, la vérification de bloc de la messagerie IF Ttransform () est un peu d'une odeur de code. Si vous Devriez-vous transformer est une préoccupation de haut niveau, distincte de l'inquiétude de faible niveau de sa mise en œuvre.
Dans le code ci-dessus, vous avez exactement une transformation commune, qui est appliquée sur tous les sprites. Si la transformation est par sprite, la transformation pourrait être comprise soit comme un attribut Vertex supplémentaire, la valeur de transformation appliquée sur tous les sommets d'un sprite. Ou vous utilisez un index de transformation (à nouveau un attribut Vertex) en un tampon uniforme. L'instanciation rend les choses encore plus concises.
Que se passe-t-il si vous n'appelez pas du tout cette fonction, ou simplement en faire une copie droite? Même pour 200 000 sommets, je ne vois pas que c'était votre gros goulot d'étranglement.
Si je rends 50k Sprites sans l'appeler, je reçois 50 fps, donc 45 fps plus. Vsync éteint.
Je vois que vous avez accepté une réponse. J'ai cependant remarqué que vous utilisez Vec4 amd mat4. Comme vous travaillez en 2D, vous n'avez besoin que de Vec2 (ou de Vec3 si vous souhaitez une profondeur Z de base) et Mat3 est nécessaire pour les transformations 2D. Voir Pourquoi les transformations 2D ont-elles besoin de matrices 3x3? qui explique ce que je veux dire . Cependant, un 3x3 peut ne pas être effectivement plus rapide en raison de l'optimisation de la SSE de Vec4 & MAT4, mais cela mérite peut-être la peine d'être testée si vous avez toujours des problèmes.